The release of Wan 2.7 Image matters for one simple reason: it is not just another model that makes pretty pictures on easy prompts. Public documentation and early hands-on reviews point to a system built for a harder job -- following complex instructions, preserving structure in editing workflows, rendering usable text inside images, and staying more coherent when multiple references, layout constraints, and production requirements collide.
That distinction is important because the AI image market is now crowded with models that look impressive in curated demos but fall apart in real work. Marketing teams need campaign assets with legible copy. Product teams need fast mockups with controlled colors. Content studios need repeatable thumbnails, storyboards, and scene variations. In those workflows, "surprising and artistic" is often less valuable than "accurate, controllable, and repeatable."
Wan 2.7 Image appears designed around that reality. The most talked-about capabilities are its reasoning-assisted generation mode, stronger prompt adherence on multi-element scenes, support for multilingual text rendering, multi-reference consistency with up to nine reference images, and batch-oriented output patterns that make it more useful for production than experimentation. At the same time, the model is not magic. It seems to trade some spontaneity and stylistic flair for precision, and several reviewers note that it is not automatically the best choice for highly painterly, taste-driven, or "surprise me" creative work.
This review focuses on what actually matters: what Wan 2.7 Image is, what the public documentation suggests, what real testers are reporting, how it compares with Wan 2.6, where the model is genuinely strong, where it still feels constrained, and how to get better results from it in practice.

What Wan 2.7 Image Actually Is
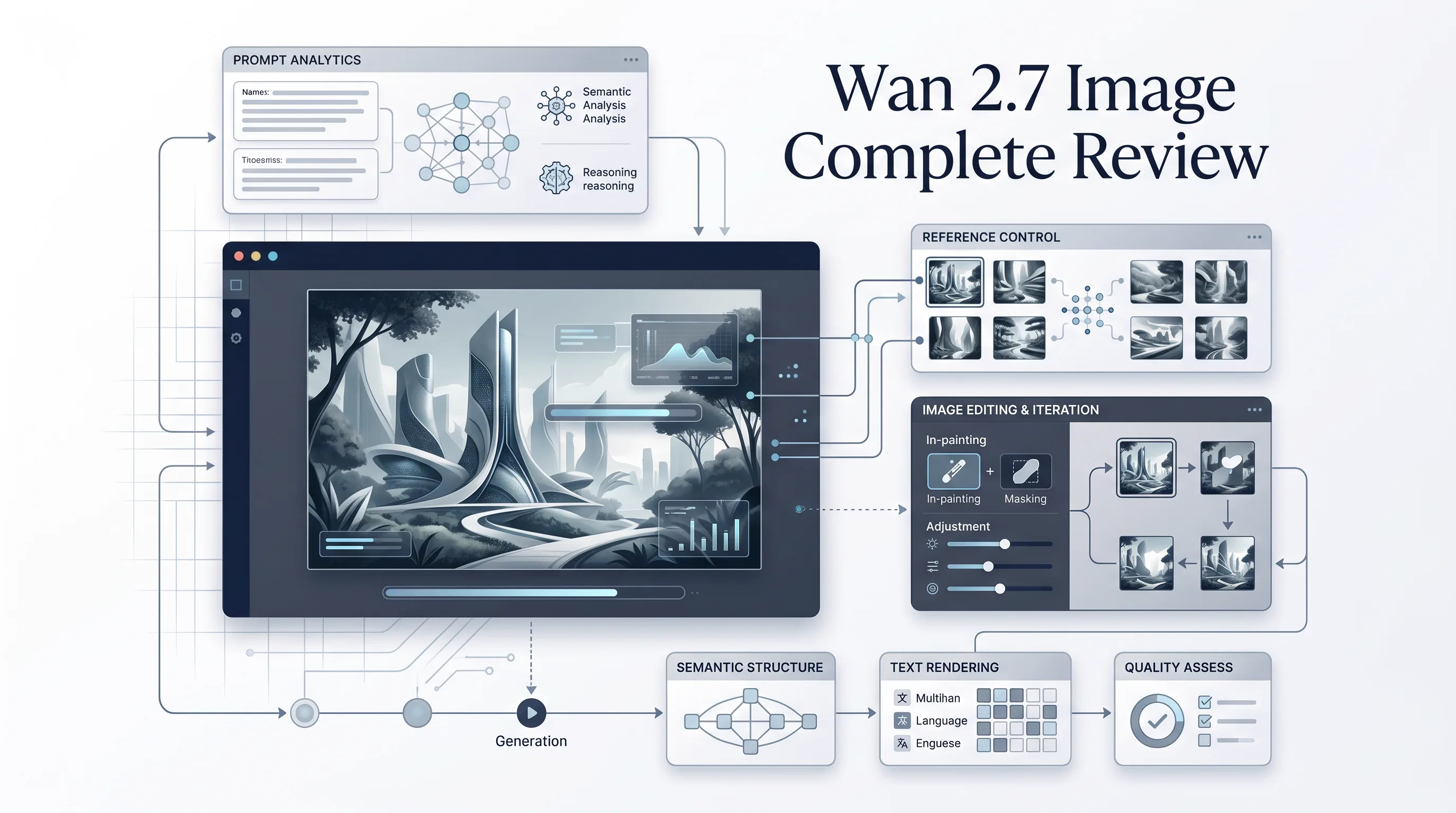
Wan 2.7 Image is best understood as a production-oriented image generation and editing family rather than a single "one-click art model." The public-facing descriptions around the release consistently emphasize four things: generation quality, controllability, text accuracy, and editing flexibility.
In practical terms, that means Wan 2.7 Image is positioned less like a toy for one-off inspiration and more like a working visual engine for creative teams. The standard version is generally described around 2K output, while the Pro tier is associated with 4K output for higher-end or print-oriented use cases. Both are discussed as part of a broader system that includes text-to-image generation and instruction-based image editing.
What makes the model stand out in discussion is not raw resolution alone. Resolution is easy to advertise. The harder and more useful claim is that Wan 2.7 Image attempts to reason through composition before rendering. In public explanations, this is framed as a "thinking mode" or "think before you draw" workflow. Whether one uses that exact marketing language or not, the point is clear: the system appears intended to reduce the usual failure modes of image generation, including collapsed compositions, missing prompt elements, weak spatial logic, and unreadable embedded text.
That matters because most frustrating AI image failures do not come from a lack of detail. They come from a lack of structure.
The Core Capability Shift: Precision Over Vibes
A lot of AI image reviews make the mistake of asking only one question: "Does it look good?" That is no longer enough. A more useful framework is this:
- Does the image follow the prompt accurately?
- Can it preserve identity, layout, or design intent across iterations?
- Can it handle text, tables, labels, or other structured visual information?
- Can a team use it repeatedly without fighting the model every time?
On those dimensions, Wan 2.7 Image looks much more interesting than many image models that dominate social media conversation.
Why the Thinking Mode Matters
The most important reported differentiator is the reasoning step before image generation. On paper, that sounds like a marketing phrase. In practice, it targets a real problem: most models are much better at aesthetics than at logic.
For example, many image generators can produce a beautiful portrait or a dramatic landscape. Fewer can reliably interpret prompts like:
- a watch in the left foreground on white marble
- a soft shadow falling right
- brass accents in the background
- readable serif headline on the top margin
- muted editorial color palette
- enough negative space for later design use
That is where Wan 2.7 Image appears strongest. Multiple reviews describe stronger prompt adherence, cleaner handling of spatial relationships, and fewer errors in multi-element scenes. The tradeoff, according to reviewers, is slightly slower generation when reasoning is enabled. For professional use, that trade usually makes sense. A slower first pass is often cheaper than five failed fast ones, especially in structured image-to-image and editing workflows.
Feature Breakdown: What the Public Web Consistently Agrees On
The ecosystem around Wan 2.7 is noisy, and many pages simply repeat release claims. Still, a few capabilities appear again and again across official docs and more practical reviews.
Wan 2.7 Image at a Glance
| Capability | What It Means in Practice | Why It Matters |
|---|---|---|
| Thinking mode | The model plans composition and semantic relationships before rendering | Better prompt adherence, especially on complex scenes |
| 12-language text rendering | Supports readable text in multiple languages inside images | Useful for posters, labels, diagrams, and presentation visuals |
| Up to 9 reference images | Multiple images can guide subject, style, or composition consistency | Better for branded series, storyboards, and iterative design |
| Standard and Pro tiers | Standard is commonly positioned around 2K, Pro around 4K | Flexible cost-quality tradeoff |
| Image editing workflow | Users can provide input images and describe changes | More useful for real production pipelines than pure text-to-image alone |
| Batch generation | Public descriptions mention multi-image generation for consistent sets | Valuable for campaigns, catalogs, and thumbnail pipelines |
These are not minor upgrades. Together, they push the model toward structured visual work rather than purely aesthetic generation.
Standard vs Pro: The Practical Difference
| Version | Practical Use Case | Strength | Limitation |
|---|---|---|---|
| Wan 2.7 Image | Fast production drafts, digital assets, iteration-heavy workflows | Strong prompt following with manageable output cost | Less suited for print-grade needs |
| Wan 2.7 Image Pro | Premium assets, detailed layouts, higher-resolution delivery | Better for final visuals and resolution-sensitive work | Likely slower and more expensive |
| Wan 2.7 Image Edit | Controlled modifications to existing images | Preserves more of the original structure | Still depends on source quality and prompt clarity |
The key decision is not "which is best," but "what are you optimizing for?" If you need rapid volume, standard output is likely enough. If you need polished hero assets, Pro makes more sense.
Where Wan 2.7 Image Looks Genuinely Strong
The most credible early praise around Wan 2.7 Image falls into four buckets.
1. Complex Prompt Adherence
This is the headline strength. Reviewers repeatedly mention that Wan 2.7 Image handles complex prompts better than many models in its class. Not just long prompts, but prompts with actual structure: foreground/background separation, directional lighting, multi-object placement, or compositional logic.
That is a bigger deal than people think. In commercial work, the prompt is usually not poetic. It is operational. The model has to understand placement, hierarchy, and role.
2. Text-in-Image Rendering
This may be the most commercially important feature of the whole release. If Wan 2.7 Image can consistently produce readable, well-placed text in 12 languages, it moves beyond being an "art generator" and becomes a design-support system.
That opens up use cases like:
- poster drafts
- packaging concepts
- charts and infographic visuals
- slides and presentation art
- product labels
- educational graphics
- social media promo cards
Many image models can fake typography from a distance. Far fewer can render it clearly enough to support real workflows.
3. Multi-Reference Consistency
The support for up to nine reference images is a major practical advantage. Most teams do not generate in a vacuum. They work from brand material, prior assets, character boards, product shots, moodboards, or campaign references.
That means Wan 2.7 Image is not just good at "making something." It is built to make something in relation to something else. That is what real creative work usually requires, and it is one reason teams will compare it against Qwen Image Edit or Seedream 5 rather than against toy generators.
4. Editing and Iteration
Instruction-based editing is often more valuable than original generation. Once a team has an image direction it likes, it usually needs refinements rather than total regeneration. Change the background. Fix the object color. Adjust the mood. Keep the face. Replace the text. Move the product. Remove the clutter.
Wan 2.7 Image appears well-positioned for this kind of iterative workflow, which is exactly where many other models become annoying.

Where Wan 2.7 Image Still Seems Limited
A credible review should not confuse capability with perfection. Based on the available material, Wan 2.7 Image still has some visible boundaries.
It is not obviously the best art director in a box
Several reviewers suggest the model's strength is precision, not artistic surprise. That means if your ideal output is dreamy, painterly, eccentric, or stylistically unexpected, other models may still feel more creatively alive.
Wan 2.7 Image seems to reward explicit instructions more than ambiguity. That is excellent for commercial reliability, but it may feel less magical for experimental image-making.
Reasoning has a speed cost
The logic-first workflow appears to improve results, but not for free. Reviewers mention slower generation compared with faster, more lightweight systems. Whether that is a real drawback depends on your workflow. For ideation jams, maybe yes. For client-facing outputs, probably not.
Prompt quality still matters
A reasoning system does not remove the need for good prompts. In fact, it may make prompt discipline more important. A model that follows instructions more faithfully will also follow bad instructions more faithfully.
If your prompt is vague, contradictory, or overloaded, Wan 2.7 Image may still produce clutter -- just more coherently cluttered.
Public information quality is uneven
One under-discussed issue is that the public web around Wan 2.7 is already full of low-trust summaries, cloned landing pages, and marketing-heavy rewrites. That creates confusion for users trying to understand what is officially supported versus what is inferred by resellers or aggregators.
So the best current reading is this: the official documentation gives a reliable baseline for supported workflows, while hands-on third-party reviews are useful for performance texture. But you should still treat a lot of web copy around the model with caution.
Wan 2.7 Image vs Wan 2.6: What Actually Changed
Wan 2.7 is not interesting because the version number is larger. It is interesting because the emphasis appears to have shifted from strong image and video lineage toward more structured and controllable image intelligence.
Practical Upgrade Table
| Dimension | Wan 2.6 | Wan 2.7 Image |
|---|---|---|
| Prompt adherence | Good, but more conventional | Stronger on complex, multi-part prompts |
| Text rendering | More limited | Major leap in multilingual, long-text handling |
| Multi-reference support | More constrained | Up to 9 references is a meaningful jump |
| Editing flexibility | Present but less emphasized | More central to the product positioning |
| Composition planning | Less visible in positioning | Reasoning-first workflow is a headline feature |
| Final-use readiness | Strong for generation | Stronger for production and iterative workflows |
The most important change is not resolution. It is control.
That is what makes Wan 2.7 Image feel like a model for teams, not just prompt hobbyists.
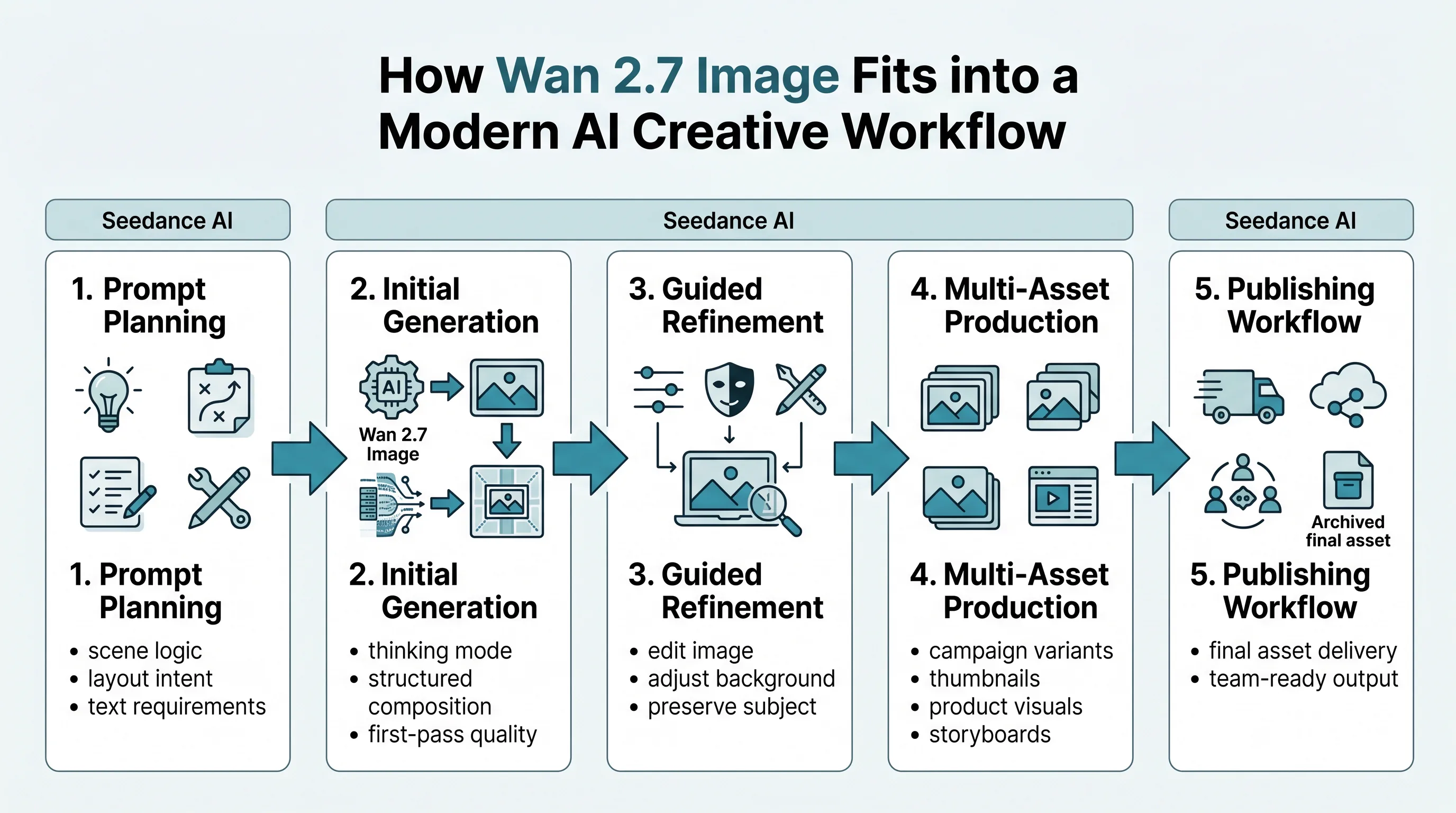
How Wan 2.7 Image Performs in Real Production Contexts
A useful way to judge the model is by workflow, not benchmark slogans.
Marketing and Brand Teams
Wan 2.7 Image is particularly well-suited to branded content creation because it combines text rendering, color control, multi-reference guidance, and layout discipline. Those are exactly the variables that matter when building ads, landing page visuals, product promos, or campaign variants.
It looks especially valuable for:
- performance marketing creatives
- e-commerce product visuals
- promotional posters
- editorial-style product art
- A/B-tested social assets
Film, Storyboarding, and Previsualization
The model's strengths in scene logic and lighting make it more useful for storyboard-like and pre-vis applications than many pure-style generators. If a creative director needs a scene with explicit spatial logic, the model seems better equipped to deliver something usable on the first pass.
Media Teams and Thumbnail Pipelines
This may be one of the most underrated use cases. Thumbnail teams care about speed, clarity, repeatability, and visual hierarchy more than abstract artistic elegance. Wan 2.7 Image seems well aligned with that reality.
Best Practices: How to Get Better Results from Wan 2.7 Image
Most users will underperform with this model if they prompt it the way they prompt looser, more improvisational systems.
Recommended Prompting Approach
- Define layout explicitly. Say foreground, background, top area, left placement, negative space, and lighting direction.
- Separate content from style. First describe what must be present. Then describe how it should look.
- Use references intentionally. Do not throw in many references without roles. Assign purpose: subject identity, palette, product angle, scene mood.
- Turn on reasoning for difficult scenes. Use it when structure matters more than raw speed.
- Use editing, not full regeneration, once direction is set. That is where this model's workflow advantage becomes real.
Prompt Framework That Fits Wan 2.7 Image
| Prompt Layer | What to Include | Example |
|---|---|---|
| Subject | Main object, person, or scene | Luxury wristwatch on marble surface |
| Composition | Placement and framing | Watch in left foreground, empty headline space above |
| Lighting | Direction, intensity, mood | Soft side light from upper left, long shadow right |
| Material detail | Surface realism and finish | Brushed steel case, matte leather strap |
| Style | Visual character | Editorial commercial photography, muted palette |
| Constraints | What to avoid | No extra objects, no warped numerals, no logo distortion |
That framework is not glamorous, but it is effective.
The Strategic Angle Most Reviews Miss
The biggest story about Wan 2.7 Image is not that it makes better pictures. It is that it narrows the gap between image generation and applied design work.
That distinction matters because the next stage of AI image adoption is not about artists posting side-by-side comparisons on social media. It is about teams replacing fragmented workflows with systems that can plan, generate, revise, and stay on-brief.
This is also where platforms matter more than isolated model access. A more practical path is a unified workflow where teams can test the model directly on a dedicated Wan 2.7 Image page, then connect the output to adjacent text to image and image to video workflows without jumping between disconnected tools.
That one-stop angle is more important than it looks. A model can be strong in isolation and still be painful in practice if the workflow around it is fragmented. The teams that gain the most from Wan 2.7 Image will likely be the ones that use it inside a broader creative stack rather than as a standalone novelty.
Final Verdict
Wan 2.7 Image looks like one of the most practically relevant image model releases in recent memory, not because it is the most artistic model on the market, but because it appears to understand what production users actually need.
Its strongest signals are clear:
- better prompt adherence on complex scenes
- useful reasoning before rendering
- much stronger text-in-image performance
- serious multi-reference support
- editing workflows that matter in real use
- clearer fit for marketing, design, pre-vis, and scaled content creation
Its limitations are also clear:
- less naturally suited to loose, highly stylized experimentation
- reasoning can cost time
- output quality still depends on prompt discipline
- the surrounding public information ecosystem is messy and inconsistent
If your main priority is beautiful randomness, Wan 2.7 Image may not be your favorite model. If your priority is controlled output, usable iterations, and less wasted time fighting the generator, it becomes a much more compelling option.
That is the real takeaway. Wan 2.7 Image is not just another model trying to impress people with isolated hero shots. It is a sign that image generation is maturing into something more operational: less about spectacle, more about control. And for serious creative teams, that is exactly the direction that matters.
FAQ
Is Wan 2.7 Image mainly for designers or for general users?
Both can use it, but the model appears especially valuable for users with structured visual goals. Designers, marketers, and content teams will likely benefit most from its prompt adherence, text rendering, and editing controls.
Is the Pro version always worth it?
Not necessarily. Use Pro when you need higher-resolution deliverables, finer detail, or more premium final assets. For rapid iteration and many digital use cases, the standard version may be enough.
What is the single most important feature?
For most real workflows, it is probably the combination of reasoning-assisted generation and text rendering. Together, they make the model much more useful than a typical pretty-picture system.
What kind of prompts suit Wan 2.7 Image best?
Prompts with explicit structure, clear composition, precise object relationships, text requirements, and controlled iteration goals.
What kind of prompts suit it less?
Highly abstract, intentionally vague, or purely style-first prompts where unpredictability is part of the desired outcome.