HappyHorse complete guide 를 찾고 있다면, 핵심은 마케팅 문구를 이해하는 데 있지 않습니다. 핵심은 지금 공개적으로 보이는 것과 독립적으로 검증 가능한 것을 구분한 뒤, HappyHorse 를 현재 시점에선 지켜볼 대상인지, 시험해볼 대상인지, 아니면 실제 제작 파이프라인에 올릴 대상인지 판단하는 것입니다.
2026년 4월 8일 기준으로 공개된 HappyHorse 자료는 상당히 야심찬 이야기를 하고 있습니다. HappyHorse 1.0 은 동기화된 오디오, 7개 언어 lip-sync, 1080p 출력, 상업적 사용 허용, self-hosting 지원, 강한 benchmark 결과를 갖춘 open-source 멀티모달 비디오 모델로 소개됩니다. 분명 매력적입니다. 하지만 동시에 검증 문제도 생깁니다. 공개 코드 경로는 직접 확인할 수 없고, 배포 예시에 나온 모델 호스팅 경로도 로그아웃 상태에서는 열리지 않기 때문입니다.
그렇다고 해서 HappyHorse 가 가짜라는 뜻은 아닙니다. 다만 이 프로젝트를 읽는 프레임은 분명해야 합니다. 흥미로운 프로젝트이지만 공개 검증은 아직 불완전하고, 프로덕션 투입 준비도도 명확하지 않다는 뜻입니다. 이 가이드에서는 무엇이 실제처럼 보이는지, 무엇이 여전히 증거를 더 필요로 하는지, HappyHorse 가 어디에서 가장 의미 있어 보이는지, 그리고 지금 바로 결과물이 필요하다면 왜 text to video 워크플로 또는 image to video 워크플로 가 더 실용적인 선택인지 정리합니다.

짧은 답
HappyHorse 는 open weights, 오디오 생성, lip-sync, self-hosting 을 내세운 유망한 AI 비디오 모델 콘셉트처럼 보입니다. 다만 현재 공개 증거만으로는 모든 headline claim 을 이미 완전히 검증된 인프라처럼 받아들이기엔 부족합니다.
실무적으로는 이렇게 보면 됩니다.
| 질문 | 실무적 답변 |
|---|---|
| HappyHorse 는 흥미로운가? | 그렇습니다. 공개 기능 조합은 개방형이면서 self-hostable 한 비디오 모델치고 상당히 공격적입니다. |
| 오늘 기준으로 완전히 검증된 공개 open model 인가? | 아직 아닙니다. 공개 저장소 경로가 열려 있지 않고, 사이트에 나온 모델 경로도 로그아웃 상태에서는 접근되지 않습니다. |
| 무시해야 하나? | 아닙니다. 오픈 멀티모달 비디오 생성에 관심이 있다면 추적할 가치가 있습니다. |
| 지금 바로 콘텐츠 파이프라인을 여기에 올려야 하나? | 검증 리스크와 불완전한 공개 산출물을 감수할 수 있을 때만 그렇습니다. |
| 크리에이터는 지금 무엇을 해야 하나? | prompt 기반 생성에는 검증된 text to video, 참조 기반 애니메이션에는 image to video 를 쓰면서 HappyHorse 는 계속 지켜보는 편이 안전합니다. |
핵심은 이렇습니다. 지금의 HappyHorse 는 당장 프로덕션의 기반이라기보다, 업사이드가 큰 관찰 대상에 더 가깝습니다.
HappyHorse 가 현재 공개적으로 주장하는 것
지금 보이는 HappyHorse 자료는 단순한 teaser 페이지가 아니라 꽤 구체적인 제품 스토리입니다. 공개적으로 보이는 주장은 다음과 같습니다.
- 15B 파라미터 모델
- 40 레이어 Transformer 아키텍처
- 비디오와 오디오의 공동 생성
- 텍스트 입력과 이미지 입력 지원
- 7개 언어 lip-sync
- 1080p 출력
- 5~8초 클립
- H100 또는 A100 급 GPU 에서 self-hosting 가능
- 상업적 사용이 가능한 open-source 릴리스
- 시작 가격
$11.90
이건 흔한 landing page 문구가 아닙니다. 창작자와 연구자 모두에게 진지하게 받아들여지길 원하는 기술 출시 페이지에 가깝습니다.
사이트에는 좀 더 구체적인 성능형 주장도 들어 있습니다.
- H100 에서 5초 1080p 클립 생성에 약 38초
- 영어, 중국어 표준어, 광둥어, 일본어, 한국어, 독일어, 프랑스어 lip-sync 지원
- OVI 1.1 과 LTX 2.3 대비 benchmark 우위
- 공개 비디오 모델 leaderboard 상위권 주장
문서만 보면 굉장히 매력적입니다. text-to-video, image-to-video, 동기화 오디오, 다국어 lip-sync, 상업 친화적 openness 를 동시에 제공하는 모델이라면 눈에 띌 수밖에 없습니다. 문제는 스토리의 완성도가 아니라, 그 스토리와 지금 실제로 접근 가능한 공개 아티팩트 사이의 간격입니다.
실제로 검증된 것과 아직 증거가 필요한 것
지금 HappyHorse 를 읽는 가장 유용한 방식은 공개 정보를 두 묶음으로 나누는 것입니다. 직접 확인 가능한 주장과, 여전히 독립 확인이 필요한 주장입니다.
| 상태 | 여기에 들어가는 것 | 그렇게 분류되는 이유 |
|---|---|---|
| 공개적으로 보이는 것 | 사이트의 기능 주장, 가격 언급, 배포 예시, benchmark 표, 샘플 비디오 | 현재 사이트에서 직접 볼 수 있고, 공개 주장으로 확인할 수 있습니다. |
| 아직 독립 검증이 부족한 것 | open-source 가용성, public weights, self-hostable codebase, 재현 가능한 benchmark 방법론, 프로덕션 readiness | 연결된 저장소 경로가 열려 있지 않고, 참조된 모델 경로도 인증 없이 접근되지 않습니다. |

이 구분이 중요한 이유는, 많은 크리에이터가 다음 두 질문을 하나로 뭉개기 때문입니다.
첫 번째 질문은,
- 이 프로젝트는 일관되고 기술적으로 그럴듯한 제품 스토리를 제시하는가?
두 번째 질문은,
- 내가 오늘 직접 검증하고, 내려받고, 재현하고, 운용할 수 있는가?
현재의 HappyHorse 는 두 번째보다 첫 번째 질문에 더 잘 답하고 있습니다.
그렇다고 프로젝트가 끝난 것은 아닙니다. 다만 올바른 행동이 달라집니다. 연구자이거나 오픈 인프라를 일찍 추적하는 편이라면 계속 지켜볼 가치가 있습니다. 반대로 마감이 있는 크리에이터라면 지금 이미 안정적으로 생성되는 툴로 계속 발행하는 편이 더 맞습니다.
왜 HappyHorse 가 주목받는가
HappyHorse 가 주목받는 이유는 크리에이터가 동시에 원하던 것들을 한데 묶어 말하기 때문입니다.
- 오픈 또는 최소한 오픈 지향 포지셔닝
- 무성 비디오가 아닌 멀티모달 생성
- 여러 언어의 lip-sync
- 순수 SaaS 의존이 아닌 self-hosting 서사
- 알려진 open video 프로젝트와 경쟁 가능해 보이게 만드는 benchmark framing
이 조합은 현재 시장의 긴장점에 정확히 닿습니다. 많은 크리에이터는 최신 비디오 시스템의 품질 향상은 원하지만, 폐쇄형 툴, 불안정한 지역별 롤아웃, 단일 표면 가격 모델에 갇히고 싶어 하지는 않습니다. HappyHorse 는 바로 그 욕구를 찌릅니다.
두 번째 이유도 있습니다. HappyHorse 는 단순히 모델이 아니라, 운영적으로 거의 완성된 것처럼 들리는 workflow 를 설명합니다. 많은 비디오 모델 페이지는 여전히 스택을 직접 조합하게 합니다. 영상은 여기서 만들고, 음성은 다른 곳에서 붙이고, lip-sync 는 또 다른 데서 수정하고, upscale 은 나중에 하고, 타이밍은 손으로 정리해야 합니다. HappyHorse 는 더 통합된 경로를 약속합니다.
그래서 공개 검증이 아직 따라오지 못해도 중요한 프로젝트처럼 보입니다. 크리에이터가 실제로 원하는 workflow 를 가리키고 있기 때문입니다.
진짜 workflow 질문: Text to Video 인가, Image to Video 인가?
나중에 HappyHorse 가 모든 공개 약속을 다 지킨다 해도, 대부분의 크리에이터는 결국 지금과 같은 핵심 선택을 해야 합니다. 출발점이 언어인지, 한 장의 프레임인지 말입니다.
이 선택은 모델 이름보다 중요합니다.
| 워크플로 | 가장 좋은 출발점 | 얻는 것 | 주요 약점 |
|---|---|---|---|
| Text to video | 아이디어, 스크립트 비트, 장면 설명, 카메라 지시는 있지만 아직 고정된 keyframe 은 없음 | 더 빠른 아이데이션, 쉬운 콘셉트 탐색, 강한 prompt 기반 변주 | 머릿속 그림이 너무 구체적일수록 구도가 흔들릴 수 있음 |
| Image to video | 이미 still image, 캐릭터 프레임, 제품 렌더, storyboard frame, hero shot 이 있음 | 더 나은 피사체 일관성, 더 타이트한 아트 디렉션, 승인된 비주얼의 애니메이션에 유리 | 원본 프레임이 약하면 큰 장면 변화에 불리함 |
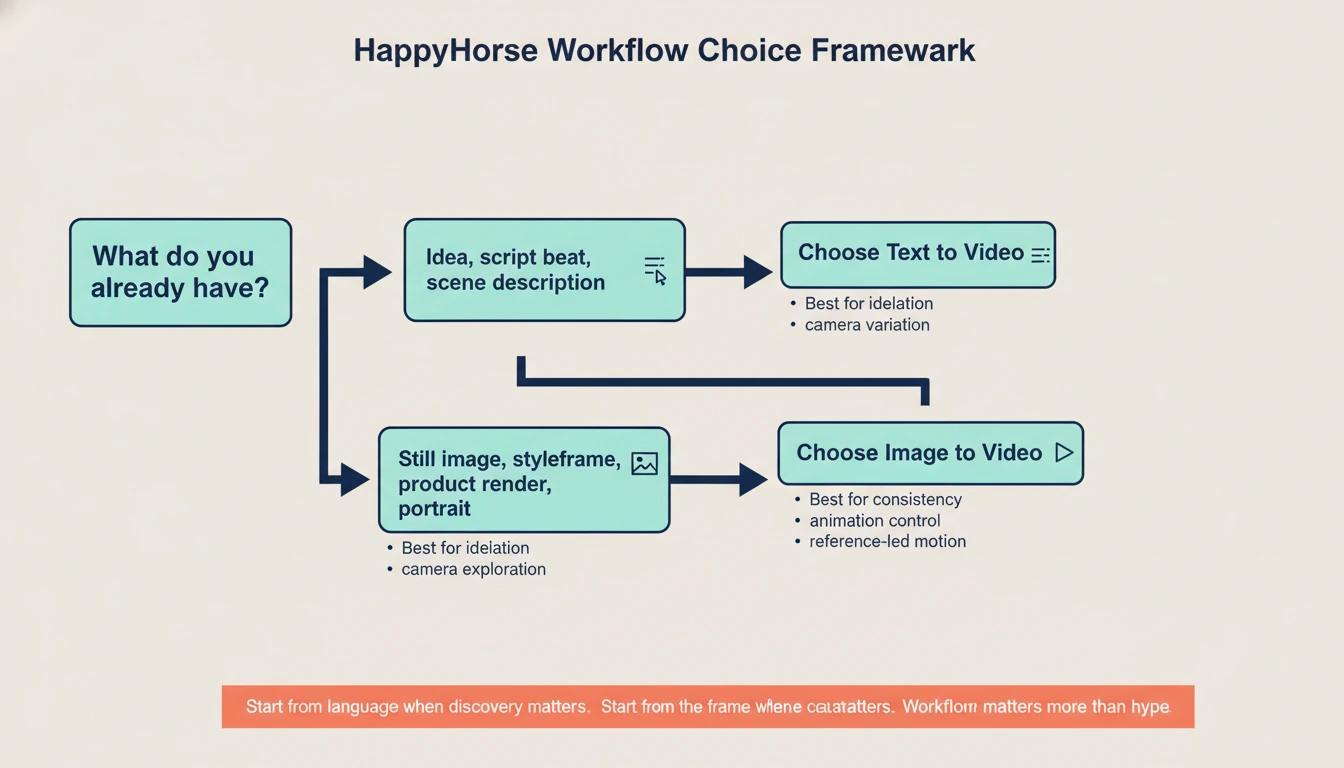
새 모델 출시를 좇다 보면 많은 사람이 바로 여기서 막힙니다. 새 모델 자체가 workflow 라고 생각하기 시작하는 것입니다. 하지만 그렇지 않습니다. workflow 는 여전히 내가 이미 가진 creative asset 에서 시작합니다.
text to video 가 맞는 경우:
- 여러 장면 아이디어를 빠르게 탐색하고 싶을 때
- 하나의 문장 콘셉트에서 여러 카메라 구성을 보고 싶을 때
- 아직 비주얼 방향을 찾는 중일 때
- 프레임을 고정하기 전에 mood, action, narrative beat 를 먼저 조정하고 싶을 때
image to video 가 맞는 경우:
- 이미 강한 정지 이미지를 가지고 있을 때
- 캐릭터, 제품, 구도를 reference 에 가깝게 유지해야 할 때
- key visual, 광고 비주얼, portrait, storyboard panel 을 애니메이션화할 때
- 열린 탐색보다 시각적 일관성이 더 중요할 때
HappyHorse 가 언젠가 두 경로를 하나의 생태계에서 모두 지원할 수는 있습니다. 하지만 대부분의 크리에이터에게 바뀌는 것은 실행 모델이지, 의사결정 트리 자체는 아닙니다.
문서상으로 HappyHorse 가 강해 보이는 지점
공개 포지셔닝이 대체로 사실에 가깝다면, HappyHorse 는 몇몇 구체적인 시나리오에서 특히 매력적일 수 있습니다.
1. 대사 중심의 짧은 영상
비디오와 오디오의 공동 생성, 그리고 다국어 lip-sync 의 조합은 이 패키지에서 가장 눈에 띄는 부분입니다. 사이트가 암시하는 수준으로 실제 동작한다면, 단순한 무성 클립 생성기와는 전혀 다른 의미를 가집니다.
이 조합은 다음과 같은 곳에서 중요합니다.
- 말하는 아바타 콘텐츠
- 짧은 설명형 영상
- 다국어 creator 영상
- 화면 속 발화가 있는 제품 소개
- 대사 중심의 소셜 콘텐츠
2. 오픈 또는 self-hosted 실험
많은 팀은 단순히 좋은 결과물만 원하는 것이 아닙니다. 직접 inspect, tune, benchmark 하고 필요하면 자체 GPU 에 배포할 수 있는 인프라를 원합니다. 그래서 open-source 각도가 중요합니다.
HappyHorse 가 실제로 usable weights, inference code, distillation options 를 내놓는다면, 이는 크리에이터뿐 아니라 다음 집단에도 의미가 생깁니다.
- applied AI 팀
- 연구 그룹
- privacy 제약이 있는 스튜디오
- 내부 미디어 파이프라인을 시험하는 기업
3. image-to-video 에서 더 강한 스타일 제어
프로젝트는 text 와 image 입력을 모두 지원한다고 말합니다. 실무적으로 보면 이미지 기반 생성이 되는 모델은 순수 텍스트 시스템보다 상업 작업에서 더 유용해지는 경우가 많습니다. image-first workflow 가 더 통제하기 쉽기 때문입니다.
그래서 HappyHorse 가 완전히 검증되기 전에도, 자신의 프로세스를 image to video 워크플로 기준으로 점검해보는 것은 의미가 있습니다. 승인된 still, styleframe, product art, character reference 에서 출발하는 제작 로직이라면, image-led animation 이 더 이식 가능한 workflow 입니다.
현재 공개 스토리의 취약한 지점
이 부분은 많은 출시 글이 건너뜁니다. 약점은 꼭 모델 자체의 약점이 아니라, 신뢰와 운용 측면의 약점입니다.
공개 아티팩트 불일치
현재 공개 자료는 완전히 출시된 기술 제품처럼 자신 있게 말합니다. 그러나 공개 repository 경로는 그 자신감을 뒷받침하지 못합니다. open-source 신뢰성을 전면에 세우려면, 접근 가능한 아티팩트는 선택 사항이 아닙니다.
benchmark 신뢰 격차
benchmark 표를 공개하는 것은 쉽습니다. 재현 가능한 평가 세부사항은 훨씬 어렵습니다. 명확히 검토할 수 있는 보고서, 안정적인 코드 접근, 제3자 재현 경로가 나오기 전까지는 benchmark 숫자를 확정 사실이 아니라 방향성 주장으로 읽는 것이 맞습니다.
프로덕션 readiness 의 모호함
모델은 실제이고 인상적일 수 있지만, 여전히 안정적 프로덕션 운용에는 준비되지 않았을 수 있습니다. 마감이 있는 팀은 보통 다음을 봅니다.
- 안정적인 접근성
- 문서화된 failure mode
- 예측 가능한 처리율
- 재현 가능한 환경
- 보이는 업데이트 cadence
HappyHorse 는 이런 항목을 평가할 만큼의 공개 운영 면을 아직 충분히 보여주지 못하고 있습니다.
지금 크리에이터가 해야 할 일
HappyHorse 가 궁금하더라도, 최선의 행동은 과대평가됐는지 과소평가됐는지 논쟁하는 것이 아닙니다. 지금 당장 자신의 워크플로에서 위험 요소를 줄이는 것입니다.
다음 표를 실전 기준으로 쓰면 됩니다.
| 현재 상황 | 지금 가장 나은 선택 |
|---|---|
| 주로 prompt 기반 콘셉트 탐색이 필요함 | 신뢰할 수 있는 text to video 워크플로 를 중심에 두고 HappyHorse 는 watchlist 로 관리 |
| 이미 concept frame, product still, portrait 가 있음 | image to video 를 중심에 두고, 더 높은 일관성을 줄 때만 새 모델 테스트 |
| 단기 발행보다 개방형 인프라가 더 중요함 | HappyHorse 를 가까이 추적하며 접근 가능한 가중치, 코드, 재현 가능한 문서를 기다림 |
| 이번 주 안에 발행 가능한 asset 이 필요함 | 공개 검증이 불완전한 모델에 콘텐츠 일정을 걸지 않음 |
많은 launch coverage 에 빠져 있는 것이 바로 이런 실무적 관점입니다. HappyHorse 가 미래인지 지금 판단할 필요는 없습니다. 오늘 무엇이 가장 안정적으로 출력을 내주는지만 판단하면 됩니다.
HappyHorse 공개 노출을 어디서 볼 수 있나
이 프로젝트가 공개 디렉터리나 출시형 소개 페이지에서 어떻게 다뤄지는지 보고 싶다면, HappyHorse AI 와 HappyHorse 비디오 모델은 눈여겨볼 만한 두 가지 참고점입니다. 둘 다 발견 경로로는 유용하지만, 검토 가능한 코드, 안정적인 가중치, 재현 가능한 배포 산출물을 대신하진 못합니다.
더 많은 공개 자료가 나오면 어떻게 평가해야 하나
HappyHorse 가 더 많은 공개 인프라를 내놓으면, 실제로 중요한 테스트는 다음과 같습니다.
- 로그아웃한 사용자가 막히는 지점 없이 실제 저장소, 문서, 모델 페이지에 도달할 수 있는가?
- 가중치, 추론 스크립트, 배포 안내가 모든 공개 표면에서 일관적인가?
- text-to-video 경로가 영화적인 프롬프트를 실용적인 수준으로 안정적으로 따르는가?
- image-to-video 경로가 motion 이 들어가도 subject 와 composition 을 유지하는가?
- 동기화 오디오는 정말 usable 한가, 아니면 여전히 많은 cleanup 이 필요한가?
- 다국어 lip-sync 주장이 몇 개의 선별된 데모를 넘어 공개적으로 계속 보이는가?
- 공개된 하드웨어 조건에서 creator 나 engineer 가 게시된 성능을 재현할 수 있는가?
이 질문들이 답을 얻기 전까지는, 적절한 태도는 informed interest 이지 blind adoption 이 아닙니다.
FAQ
HappyHorse 는 지금 open source 인가요?
HappyHorse 는 상업적 사용이 가능한 open source 로 공개적으로 소개되지만, 현재 공개 저장소 경로는 직접 확인 시 접근되지 않습니다. open-source claim 은 보이지만, 공개 아티팩트 체인은 아직 완성되지 않았습니다.
HappyHorse 는 text-to-video 인가요, image-to-video 인가요?
현재 공개 사이트에서는 둘 다라고 설명합니다. 그것도 관심을 끄는 이유 중 하나입니다. 더 중요한 질문은 지금의 입력에 어떤 workflow 가 맞느냐입니다. prompt 기반 아이데이션이면 text to video, reference 기반 애니메이션이면 image to video 가 맞습니다.
HappyHorse 는 프로덕션에 쓸 준비가 되었나요?
향후에는 프로덕션 관련성이 생길 수 있지만, 지금의 공개 검증 수준으로는 마감 민감한 파이프라인의 중심으로 추천하기엔 아직 이릅니다.
왜 이렇게 많은 사람이 HappyHorse 에 관심을 가지나요?
오픈 모델 포지셔닝에 동기화 오디오, 다국어 lip-sync, 텍스트와 이미지 양쪽 입력을 결합했기 때문입니다. 단일 benchmark 스크린샷만 있는 또 다른 무성 비디오 모델보다 훨씬 매력적인 workflow 스토리입니다.
HappyHorse 가 성숙해질 때까지 무엇을 써야 하나요?
workflow-first 로 생각하세요. 장면이 아직 prompt 중심이라면 text to video, 이미 움직이고 싶은 프레임이 있다면 image to video 를 쓰는 것이 자연스럽습니다.
최종 판단
HappyHorse 는 주목할 가치가 있지만, 맹신할 대상은 아닙니다. 공개 스토리는 진지하게 추적할 만큼 강하고, 동시에 강하게 검증해야 할 만큼 아직 약합니다.
만약 앞으로 현재의 공개 claim 을 안정적인 아티팩트와 함께 실제로 이행한다면, HappyHorse 는 시장에서 가장 흥미로운 open video 프로젝트 중 하나가 될 수 있습니다. 그전까지는 launch page 의 흥분을 production dependency 로 바꾸지 않는 것이 좋습니다. 오늘 이미 발행을 도와주는 workflow 위에서 계속 만들고, 평가 기준은 높게 유지한 채, HappyHorse 는 아직 증거의 공백을 메우는 중인 유망 프로젝트로 다루는 것이 가장 현실적입니다.